Information Extraction from Nepali Government Documents Using YOLOv8
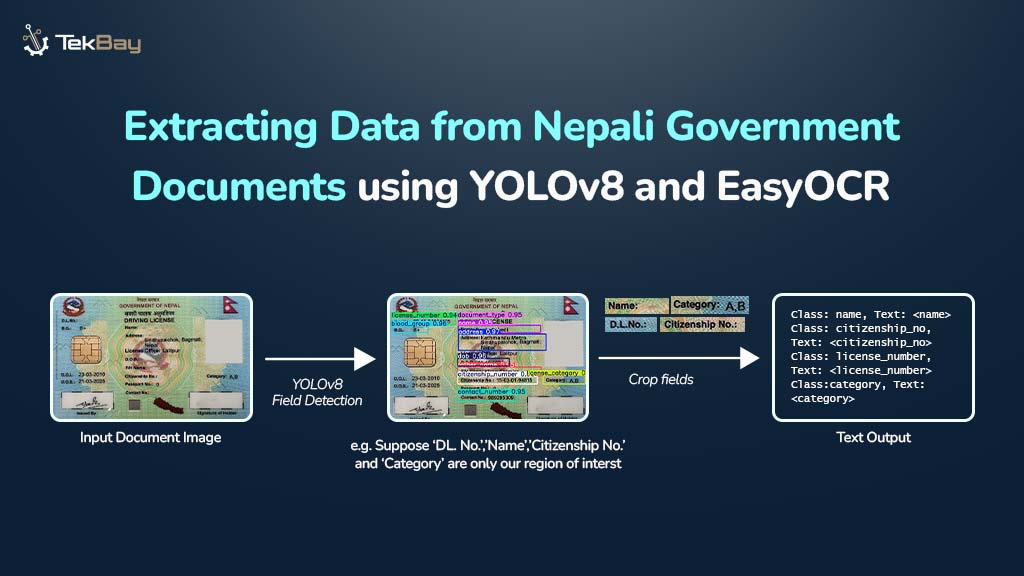
Standard Optical Character Recognition (OCR) technologies often struggle to extract information from complex, semi-structured government documents, such as Nepali driving licenses. These documents feature unique layouts, mixed languages (Nepali and English), and custom fonts, which can cause generic OCR systems to produce inaccurate and unreliable results. The blog introduces a two-step approach to tackle these […]
Automating Train-and-Deploy ML Workflows with Amazon SageMaker Pipelines
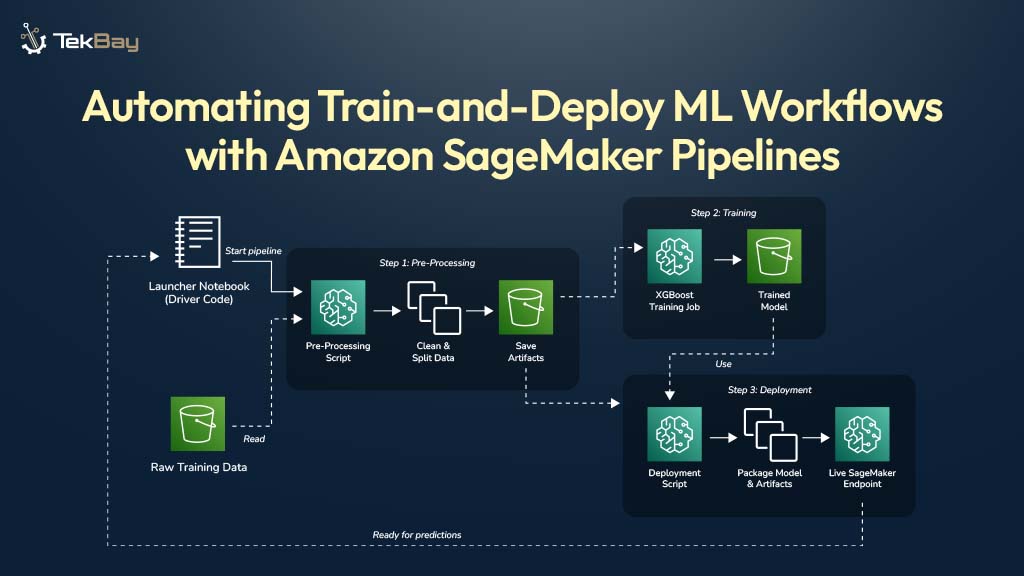
Jupyter Notebooks are excellent for exploring data and building machine learning models. However, retraining these models on new data by manually re-running notebook cells can be slow and prone to errors. When it is time to retrain a model on new data, practitioners often face the challenge of re-running numerous cells in the correct sequence, […]