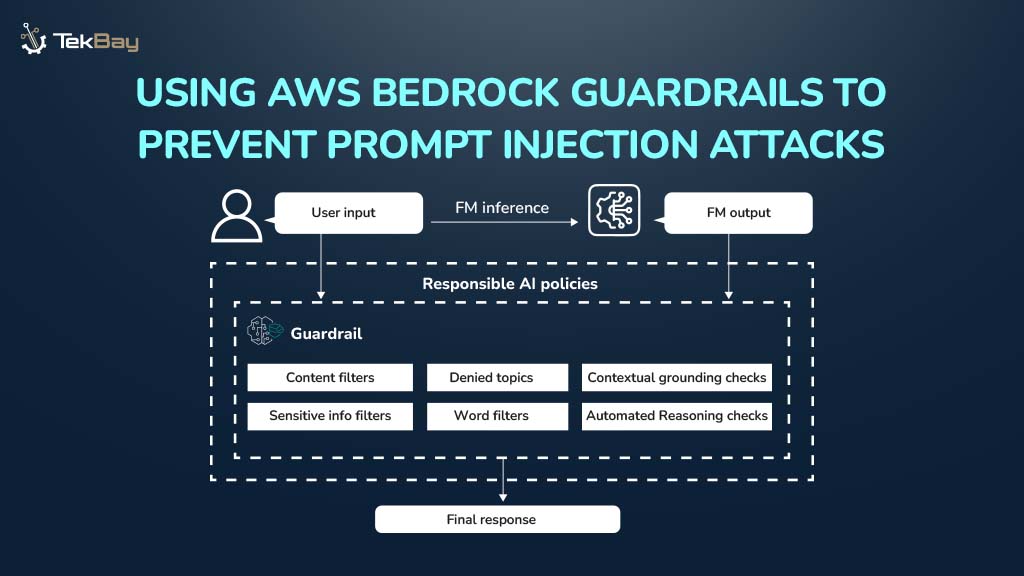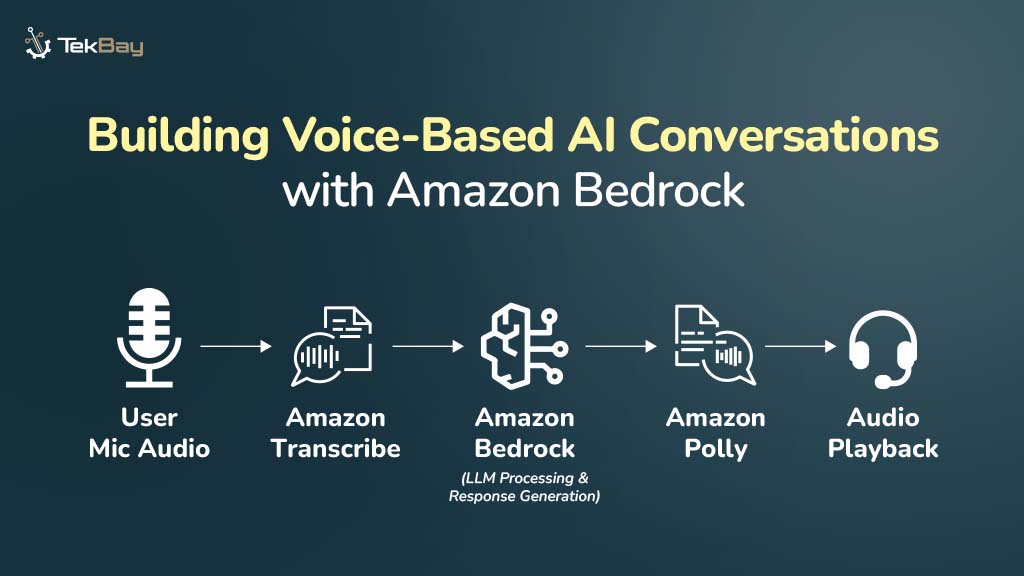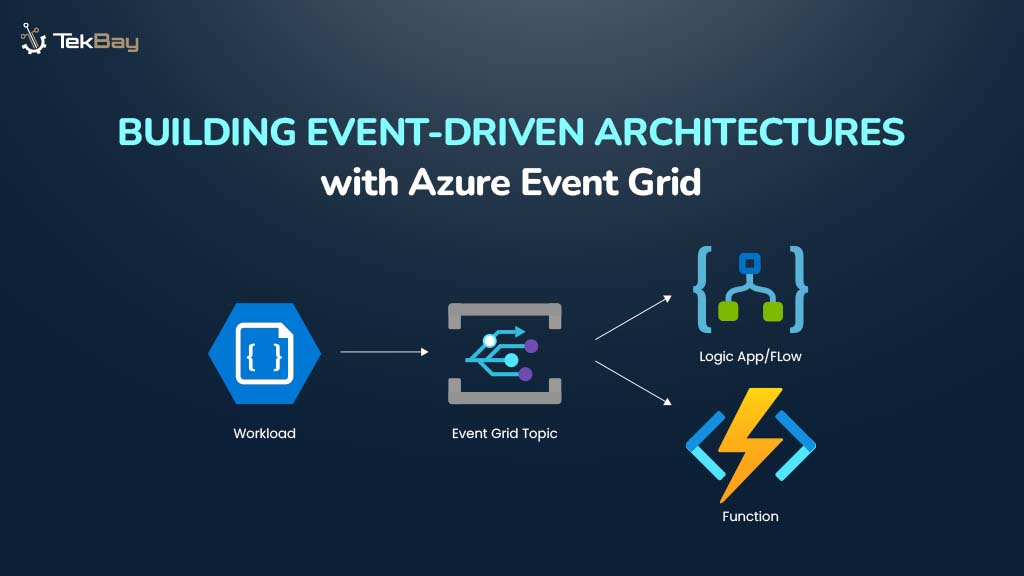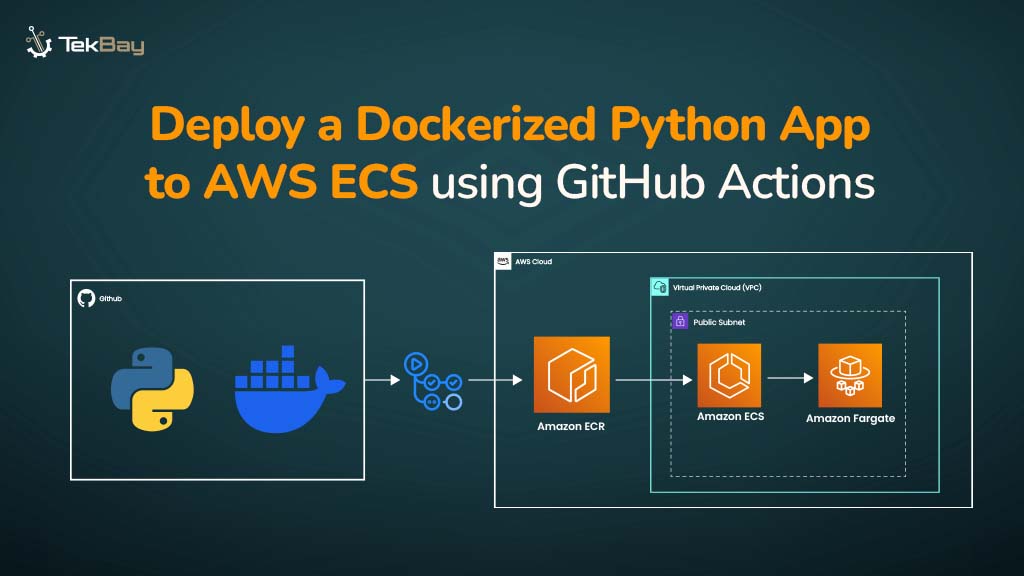
Fine-tuning foundation models on Amazon Bedrock allows you to customize AI models for your specific use case. In this hands-on tutorial, we’ll walk through the complete process of fine-tuning a model on Amazon Bedrock, from data preparation to deployment.
What We’ll Build In This Amazon Bedrock Fine-Tuning Tutorial
By the end of this tutorial, you’ll have:
- A fine-tuned Amazon Titan model customized for your domain
- Complete understanding of the fine-tuning workflow
- Production-ready code for your own implementations
Prerequisites
Before going through the steps, ensure to have the following:
- AWS account with Bedrock access enabled
- AWS CLI configured with appropriate permissions
- Python 3.8+ with boto3 installed
- Basic understanding of machine learning concepts
Steps To Fine-Tune AI Models on Amazon Bedrock
Step 1: Enable Amazon Bedrock Access
First, we need to request access to Amazon Bedrock models.
- Navigate to the Amazon Bedrock console
- Go to “Model access” in the left sidebar
- Click “Manage model access.”

- Select the models you want to use (for this tutorial, select “Amazon Titan Text G1 – Express”)
- Click “Request model access.”

Note: Model access approval can take a few minutes to several hours, depending on the model.
Step 2: Set Up IAM Permissions
Create an IAM role that Bedrock can use for fine-tuning operations.
- Go to the IAM console.
- Click “Roles” → “Create role.”
- Attach the following policies:
AmazonBedrockFullAccessAmazonS3FullAccess(for accessing training data)
- Name your role
bedrock-full-access. - Note the Role ARN – we’ll use it later.

Step 3: Prepare Your Training Data
For this example, we’ll create a customer service chatbot training dataset.
Create Training Data
Create a file named training_data.jsonl with the following format:
{"prompt": "How do I reset my password?", "completion": "To reset your password: 1. Go to the login page 2. Click 'Forgot Password' 3. Enter your email address 4. Check your email for reset instructions 5. Follow the link to create a new password"}
{"prompt": "What are your business hours?", "completion": "Our customer service is available Monday through Friday, 9 AM to 6 PM EST. For urgent issues outside these hours, please email support@company.com"}
{"prompt": "How do I cancel my subscription?", "completion": "To cancel your subscription: 1. Log into your account 2. Go to Account Settings 3. Click on Subscription 4. Select 'Cancel Subscription' 5. Confirm cancellation. You'll retain access until your billing period ends"}
{"prompt": "Where can I track my order?", "completion": "You can track your order by: 1. Logging into your account 2. Going to 'My Orders' 3. Clicking on the order number 4. Viewing tracking information. You'll also receive tracking updates via email"}
{"prompt": "Do you offer refunds?", "completion": "Yes, we offer refunds within 30 days of purchase. To request a refund: 1. Contact our support team 2. Provide your order number 3. Explain the reason for refund 4. We'll process it within 3-5 business days"}Validation Data (Optional)
Create validation_data.jsonl for model evaluation:
{"prompt": "How long does shipping take?", "completion": "Standard shipping takes 5-7 business days. Express shipping takes 2-3 business days. Free shipping is available on orders over $50"}
{"prompt": "Can I change my order after placing it?", "completion": "You can modify your order within 1 hour of placing it by contacting customer service. After that, the order enters processing and cannot be changed"}Data Quality Tips
For better results:
- Consistent Format: Keep prompt/completion structure uniform
- Representative Examples: Cover all scenarios your model will encounter
- Quality over Quantity: 100 high-quality examples often outperform 1000 poor ones
- Length Balance: Mix short and detailed responses
Step 4: Upload Data to S3
Create an S3 bucket and upload your training data:
# Create S3 bucket
aws s3 mb s3://bedrock-finetuning-bucket
# Upload training data
aws s3 cp training_data.jsonl s3://bedrock-finetuning-bucket/data/training_data.jsonl
# Upload validation data (optional)
aws s3 cp validation_data.jsonl s3://bedrock-finetuning-bucket/data/validation_data.jsonl

Step 5: Create the Fine-Tuning Job
Now we’ll create the fine-tuning job using the AWS Console.
5.1 Using AWS Console
- Navigate to the Amazon Bedrock console.
- Click “Custom models” in the left sidebar.
- Click “Create custom model.”

- Fill in the model details:
- Model name:
customer-service-chatbot-v1 - Base model:
Amazon Titan Text G1 - Express - Customization method:
Fine-tuning
- Model name:
- Configure training settings:
- Training data location:
s3://bedrock-finetuning-bucket/data/training_data.jsonl - Validation data location:
s3://bedrock-finetuning-bucket/data/validation_data.jsonl - Output data location:
s3://bedrock-finetuning-bucket/output/
- Training data location:

- Set hyperparameters:
- Learning rate:
0.0001 - Batch size:
1 - Epochs:
3
- Learning rate:

- Select the IAM role we created earlier: bedrock-full-access.
- Click “Create custom model.”
5.2 Using Python SDK (Alternative)
import boto3
import json
# Initialize Bedrock client
bedrock = boto3.client('bedrock', region_name='us-east-1')
# Create fine-tuning job
response = bedrock.create_model_customization_job(
jobName='customer-service-chatbot-job',
customModelName='customer-service-chatbot-v1',
roleArn='arn:aws:iam::123456789012:role/BedrockFineTuningRole',
baseModelIdentifier='amazon.titan-text-express-v1',
trainingDataConfig={
'S3Uri': 's3://bedrock-finetuning-bucket/data/training_data.jsonl'
},
validationDataConfig={
'S3Uri': 's3://bedrock-finetuning-bucket/data/validation_data.jsonl'
},
outputDataConfig={
'S3Uri': 's3://bedrock-finetuning-bucket/output/'
},
hyperParameters={
'epochCount': '3',
'batchSize': '1',
'learningRate': '0.0001'
},
tags={
'Environment': 'Development',
'Project': 'Customer-Service-Bot'
}
)
print(f"Fine-tuning job created: {response['jobArn']}")Step 6: Monitor Training Progress
- Go to “Custom models” in the Bedrock console.
- Find your model and click on it.
Step 7: Test Your Fine-Tuned Model
Once training completes, you can test your model.
Get Model ARN
- In the Bedrock console, go to “Custom models.”
- Find your completed model.
- Copy the Model ARN.
Test Using AWS Console
- Go to the “Text” playground in the Bedrock console
- Select your custom model from the dropdown
- Enter a test prompt: “How do I reset my password?”
- Click “Run” and observe the response
Conclusion
This guide provides an end-to-end approach to fine-tuning foundation models on Amazon Bedrock, enabling organizations to customize AI models for specific business or research use cases.
Key Takeaways:
- Prioritize data quality: High-quality datasets are essential for effective fine-tuning.
- Start with small experiments: Validate approaches before scaling up.
- Monitor model performance: Track training metrics and adjust as needed.
- Optimize costs: Manage compute resources and experiment strategically to control expenses.
- Plan for production deployment: Ensure models are monitored and maintained in real-world scenarios.
The code repository shared in this guide serves as a reusable framework for future fine-tuning projects, allowing experimentation with different models, datasets, and hyperparameters to achieve highly specialized, production-ready AI models using Amazon Bedrock.