Voice interfaces are becoming the new normal for interacting with technology, from virtual assistants like Alexa and Siri to customer service chatbots and language tutors. However, building a robust, real-time voice conversation system that understands natural speech and responds fluently is a challenging task.
In this blog, we’ll explore how to build a live voice AI conversation application using Amazon Bedrock foundation models, alongside AWS services such as Amazon Transcribe and Amazon Polly. You’ll see how these tools work together to enable seamless speech-to-text, natural language understanding, and text-to-speech synthesis, all streaming in real-time.
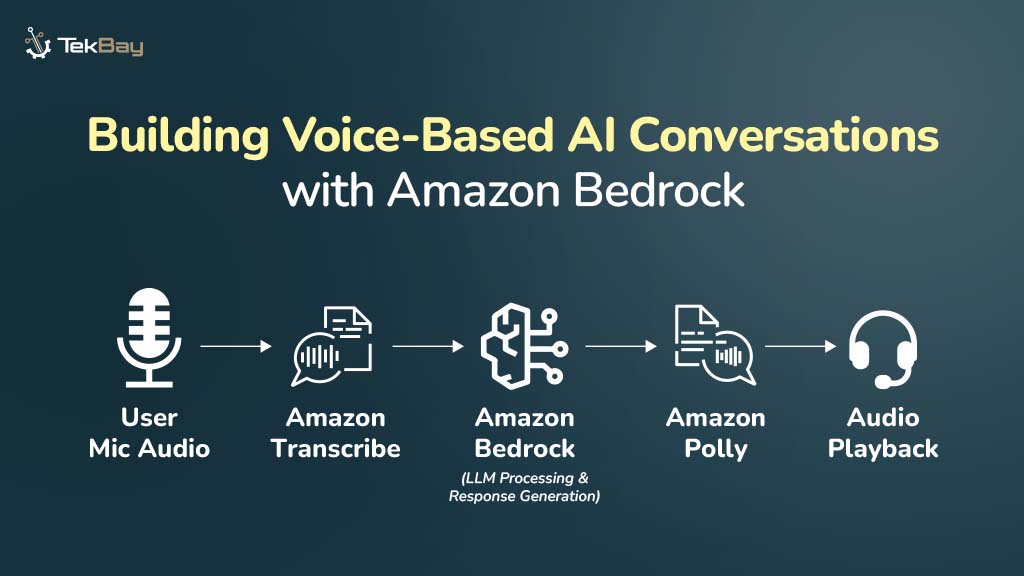
Architecture Overview
At a high level, the system works as follows:
User Mic Audio
↓ (streaming)
Amazon Transcribe (Speech-to-Text)
↓ (transcription stream)
Buffering & Text Processing
↓ (synchronous request)
Amazon Bedrock (Foundation Model)
↓ (response stream)
Amazon Polly (Text-to-Speech)
↓ (audio stream)
Audio Playback to User- Amazon Transcribe captures your microphone audio and transcribes speech into text in near real-time.
- The transcribed text is buffered and sent as a prompt to an Amazon Bedrock foundation model like Titan, Claude, or Jurassic for AI text generation.
- The AI-generated text response streams back from Bedrock and is converted to speech by Amazon Polly.
- Polly’s synthesized speech plays through the user’s speakers, creating a real-time conversational experience.
Why Use Amazon Bedrock for Voice AI?
Amazon Bedrock provides easy access to powerful foundation models from multiple providers with a consistent API and AWS security. This means you can:
- Leverage state-of-the-art LLMs without managing infrastructure.
- Use streaming response APIs for low latency.
- Integrate seamlessly with AWS services like Transcribe and Polly.
- Choose different models optimized for chat, completion, or specialized domains.
Getting Started
- Set your AWS credentials with permissions for Amazon Bedrock, Transcribe, and Polly.
- Set environment variables for model and region:
export MODEL_ID=amazon.titan-text-express-v1 export AWS_REGION=us-east-1- Run the Python application.
- Speak into your microphone and hear the AI respond in real time!
Steps To Build a Voice-Based AI Conversations Application with Amazon Bedrock
Step 1: Capture and Stream Microphone Audio to Amazon Transcribe
Using the sounddevice library, we capture PCM audio chunks and asynchronously stream them to Transcribe.
async def mic_stream(self):
loop = asyncio.get_event_loop()
input_queue = asyncio.Queue()
def callback(indata, frame_count, time_info, status):
loop.call_soon_threadsafe(input_queue.put_nowait, (bytes(indata), status))
stream = sounddevice.RawInputStream(
channels=1, samplerate=16000, callback=callback, blocksize=4096, dtype="int16"
)
with stream:
while True:
indata, status = await input_queue.get()
yield indata, statusStep: Handle Transcription Events and Buffer Text
Transcription results come as partial or final. We collect finalized sentences before sending them to Bedrock.
class EventHandler(TranscriptResultStreamHandler):
text_buffer = []
async def handle_transcript_event(self, transcript_event):
results = transcript_event.transcript.results
if results:
for result in results:
if not result.is_partial:
for alt in result.alternatives:
self.text_buffer.append(alt.transcript)
# When buffer has enough text or silence detected, trigger Bedrock call
if len(self.text_buffer) > 0 and self.is_silence_detected():
input_text = ' '.join(self.text_buffer)
self.text_buffer.clear()
# Invoke Bedrock in background
executor.submit(bedrock_wrapper.invoke_bedrock, input_text)Step 3: Invoke Amazon Bedrock Foundation Model
We build the API request body depending on the model and call Bedrock’s streaming response endpoint.
def invoke_bedrock(self, prompt_text):
body = {
"inputText": prompt_text
}
response = bedrock_runtime.invoke_model_with_response_stream(
modelId=self.model_id,
body=json.dumps(body),
accept="application/json",
contentType="application/json"
)
for event in response.get('body'):
text_chunk = extract_text_from_event(event)
self.handle_text_chunk(text_chunk)Step 4: Convert Text Response to Speech with Polly
Text chunks from Bedrock are fed into Polly for speech synthesis and played in real time.
def read_and_play_audio(text):
response = polly.synthesize_speech(
Text=text,
Engine='neural',
VoiceId='Joanna',
OutputFormat='pcm',
LanguageCode='en-US'
)
audio_stream = response['AudioStream']
while True:
data = audio_stream.read(1024)
if not data:
break
audio_output.write(data)Tips for a Smooth Voice Conversation Experience
- Buffering: Group transcribed text into meaningful chunks before sending to Bedrock to provide better context and reduce jitter.
- Latency: Use asynchronous streaming and threading to keep audio and text flowing smoothly without blocking.
- Cost: Monitor Bedrock usage carefully, as per-second streaming and foundation model calls can add up.
- Security: Encrypt audio and text streams, and manage AWS IAM permissions tightly.
- Model Choice: Pick a model based on your use case. Chat-optimized models like Anthropic Claude work great for conversational AI.
Use Cases
- AI-powered voice interview agents like Skillect
- Voice-enabled customer support bots
- Language learning tutors and pronunciation coaches
- Hands-free productivity assistants
Conclusion
Building voice-based AI conversations no longer requires stitching together complex infrastructure. With Amazon Bedrock’s powerful foundation models and AWS’s real-time streaming services, you can create natural, interactive voice experiences quickly and at scale.
Try out the code, experiment with different models, and unlock the future of voice AI!